首页
问答
文章
专栏
大咖
更多
话题
帮助
专题
悬赏
投票
请输入关键字进行搜索
查看更多 "
" 的搜索结果
登录
百果量化交流平台
百果量化交流平台
搜索
推荐
最新
热门
待回答
悬赏
文章
顶
沪深交易所LV2行情数据的详细介绍
该资料详细介绍了沪深交易所LV2行情数据与LV1的区别,对要想使用LV2行情数据的朋友有非常大的帮助。
系统
PTrade
赞同
1
593 浏览
0 评论
ptrade小助手
2025-12-04 10:49
文章
顶
PTrade系统量化交易与回测的区别
本资料主要介绍了PTrade的回测和交易的具体区别事项,对PTrade初学者有非常大的帮忙。
使用说明
系统
PTrade
赞同
1
1523 浏览
2 评论
ptrade小助手
2025-10-27 16:28
文章
顶
持久化在量化策略中的重要性与应用
策略在运行过程中产生的一些数据信息,比如股票池、账户信息、订单信息,这些数据是存储在内存中的,如果遇到服务器异常或者策略优化更新之后重启策略,这些数据都会丢失,导致策略运行失真或报错。持久化即是将这些数据存储到硬盘中,这样数据就不会丢失,量...
PTrade
赞同
0
1232 浏览
0 评论
大观量化
2025-09-24 03:39
文章
顶
PTrade新系统API帮助文档(新主干版本)
恒生电子的PTrade系统自从2019推向市场以来,收到广大专业投资者的喜爱,但在使用过程中因为Python(3.5.1)系统版本太低造成许多难以克服的问题。经过恒生半年的努力,终于在2024年10月推出了基于Python(3.11)的新版...
使用说明
系统
PTrade
赞同
11
10086 浏览
9 评论
ptrade小助手
2024-10-24 11:26
文章
顶
如何使用PTrade发送邮件函数(send_email)
PTrade系统有一个专门发送邮件的函数,很多客户使用过遇到不少问题,这个资料就是详细介绍这个函数的使用。
使用说明
PTrade
赞同
1
1450 浏览
4 评论
ptrade小助手
2025-07-29 16:48
文章
顶
PTrade系统涉及到LV2行情接口函数介绍(新版本)
随着越来越多的券商PTrade系统推出LV2行情,我们整理了一份PTrade系统里能调用LV2的函数说明供大家参考。
使用说明
系统
PTrade
赞同
2
2136 浏览
6 评论
ptrade小助手
2025-06-11 11:08
文章
顶
PTrade用户常见问题与解答汇总
本文系作者根据山西证券ptrade技术支持群中群友的常见提问,结合自身经验整理出多个使用PTrade时的常见问题、原因与解决方法供参考。文中的问题原因是最常见的,提供的解决方法在大多数情况下有效,但一个问题可由多个原因引发,如果按文中的解决...
PTrade
赞同
4
3261 浏览
1 评论
大观量化
2025-06-06 02:21
文章
顶
新版本PTrade系统的特点(新主干版本)
恒生云纪新推出的新版本PTrade系统与原来老版本有比较大的区别,具体改进的地方见附件资料。
使用说明
系统
PTrade
赞同
6
3043 浏览
1 评论
ptrade小助手
2025-03-17 15:52
文章
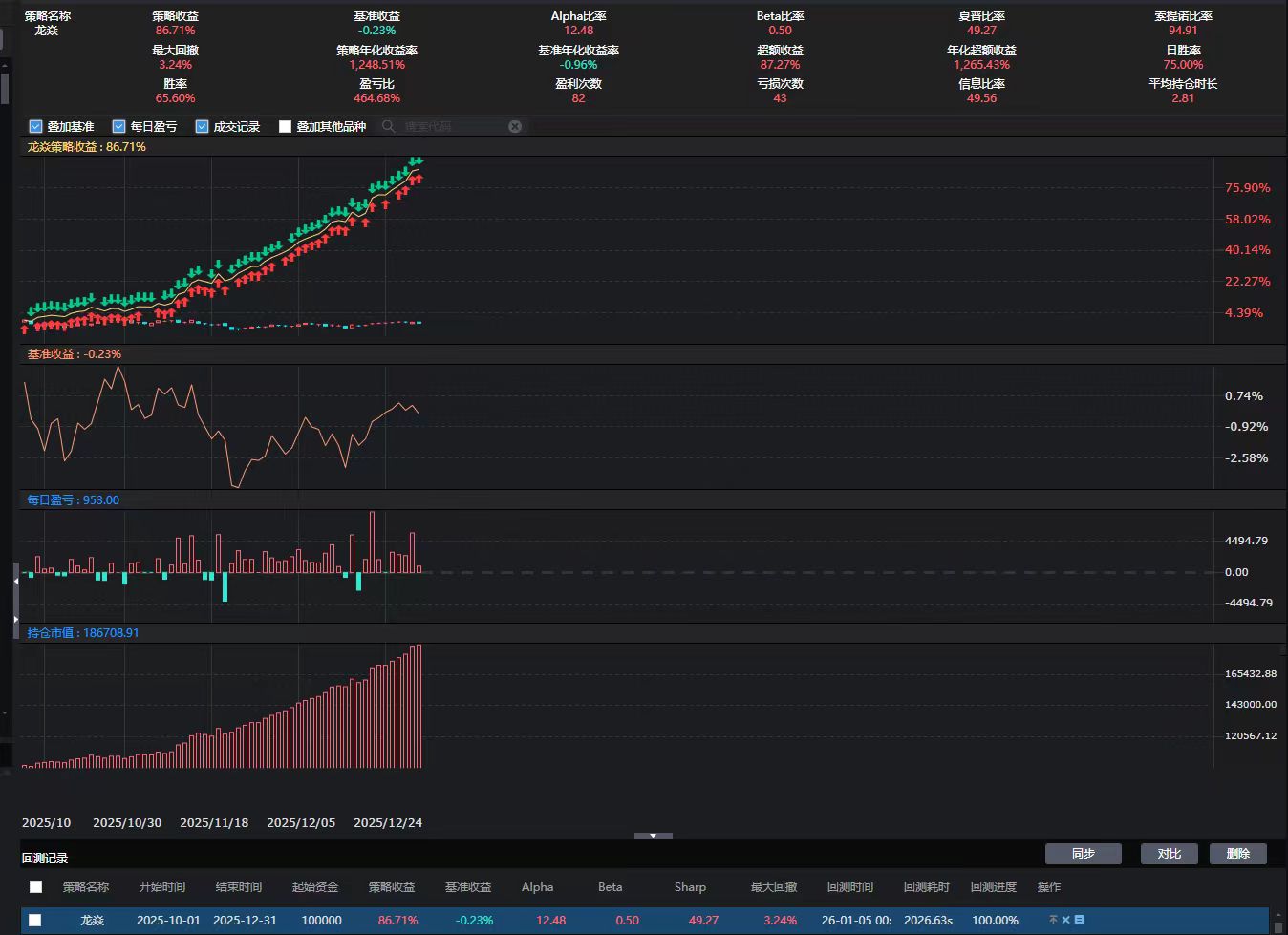
龙焱动量突破型短线策略,收益稳健,效果真实
各位,我有数个非常优秀的ptrade量化策略包括小市值,打板,一进二等等,为了扩大自己的策略,也扩展一些思路,想和拥有优秀策略的朋友交换,截图龙焱短线动量策略,感兴趣,可联系WX:Q18056075858.
PTrade
策略
赞同
0
52 浏览
0 评论
钱府上士
2 天前
文章
券商量化研报--金融工程研报精选(2026.01.30)
券商名称 分析师 研报标题 日期 开源证券 魏建榕 12月转债配置:转债估值偏贵,看好偏股低估风格-金融工程定期 2025/12...
财经消息
赞同
0
44 浏览
0 评论
慧选牛牛
3 天前
文章
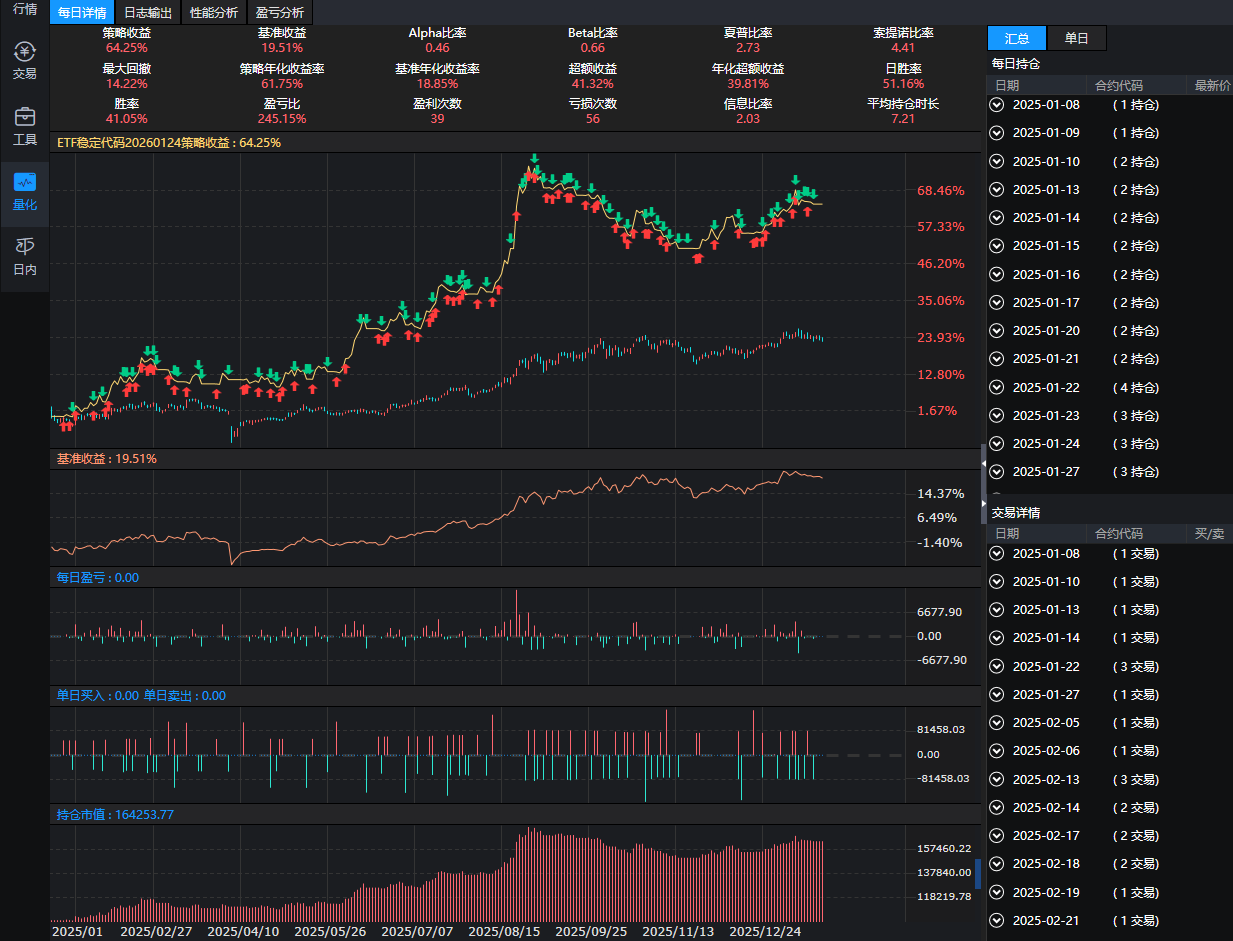
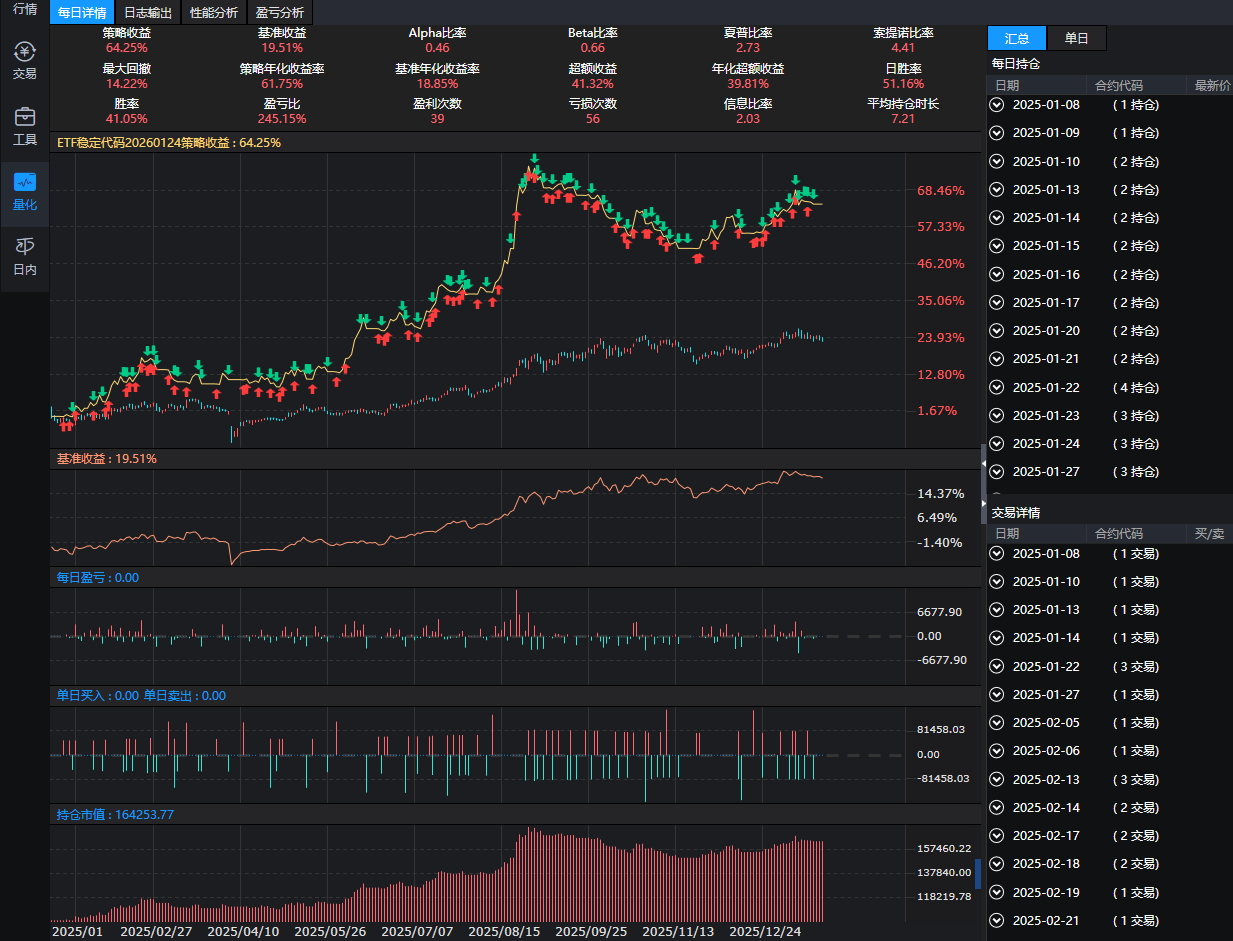
ETF稳定策略
每年也有稳定不错的固定收益。本人写了一个类似的代码,如果你想购买作为你投资的参考,。注意:1.本代码仅供学习使用,风险自担。2.代码
PTrade
策略
赞同
0
140 浏览
0 评论
绝处逢生
2026-01-24 18:53
文章
ptrade龙头股票代码
非诚勿扰
PTrade
策略
赞同
0
159 浏览
0 评论
绝处逢生
2026-01-24 18:52
文章
闲置资金管理神器--自动逆回购工具来了
自动化逆回购策略策略概述这是一个专为闲置资金管理设计的自动化逆回购策略,每天在固定时间(14:59)自动买入1天期国债逆回购,实现资金的高效利用。策略逻辑简单直接,适合希望自动化管理闲散资金的投资者。核心特点完全自动化每日14:59自动执行...
系统
PTrade
策略
赞同
0
164 浏览
0 评论
自动交易
2026-01-23 12:20
kk525
发起了提问
2026-01-23 12:20
PTrade
问答
请教大家:PTrade 竞价的未匹配量红绿柱如何用代码定义出来的?
PTrade 竞价的未匹配量红绿柱如何用代码定义出来的?
:
关注问题
1
0
0 评论
文章
券商量化研报--金融工程研报精选(2026.01.23)
券商名称 分析师 研报标题 日期 信达证券 于明明 短期压力有所缓解,市场进入温和修复阶段-金工点评报告 2025/12/6 ...
财经消息
赞同
0
106 浏览
0 评论
慧选牛牛
2026-01-23 09:52
«
1
2
3
4
5
6
7
8
...
40
41
»
写回答
提问题
写文章
站点公告
关于支付系统公告
目前支付系统升级中,仅支持PC端扫码支付,以及用其他移动端扫码支付,暂不支持二维码识别支付,给您带来不便深表歉意
提现系统公告
提现系统升级中,目前提现系统中比例与实际不相同,提现请联系管理员,且提现比例以实际为准
热门话题
加密平台
讨论:
1
关注:
2
使用说明
讨论:
34
关注:
14
工具
讨论:
8
关注:
3
数据
讨论:
3
关注:
1
系统
讨论:
72
关注:
4
热门专栏
追风中年
文章:
14
浏览:
32732
聚宽论坛策略移植PTrade平台
文章:
6
浏览:
15483
Tushare数据
文章:
3
浏览:
5086
【新版PTrade系统】Python库介绍
文章:
4
浏览:
37936
打板策略专栏
文章:
1
浏览:
224
热门用户
kings802
提问:
1
获赞:
0
赛古珑
提问:
0
获赞:
5
量化交流搬运工
提问:
0
获赞:
3
timi
提问:
0
获赞:
13
多宝楼主
提问:
0
获赞:
2
友情链接:
tushare数据接口
tushare数据工具
All Rights Reserved © 2026
京ICP备2021012325号
京公网安备11011502037708号
关于我们
社区规范
你的浏览器版本过低,可能导致网站部分内容不能正常使用!
为了能正常使用网站功能,请使用以下浏览器
Chrome
Firefox
Safari
IE 10+